The polynomial decomposition
Introduction
The polynomial decomposition approach was originally proposed by Keery et al. (2012). It consists of performing Debye decomposition of the SIP spectra with the assumption that the relaxation time distribution (RTD) of that spectra can be approximated by a polynomial function. In this approach, the complex resistivity \(\rho^*\) is given by
\begin{equation} \rho^* = \rho_0 \left[ 1 - \sum_{l=1}^{L} m_l\left(1-\frac{1}{1+(i\omega\tau_l)} \right) \right], \end{equation}
where \(\omega\) is the measurement angular frequencies (\(\omega=2\pi f\)) and \(i\) is the imaginary unit. BISIP uses a generalized Cole-Cole polynomial decomposition scheme by including a user-defined Cole-Cole exponent (\(c\)). If \(c = 1\), the equation is equivalent to Debye decomposition. If \(c=0.5\), the equation is known as Warburg decomposition. For any other values we refer to this scheme as the generalized Cole-Cole decomposition. The complex resistivity is thus given by
\begin{equation} \rho^* = \rho_0 \left[ 1 - \sum_{l=1}^{L} m_l\left(1-\frac{1}{1+(i\omega\tau_l)^c} \right) \right], \end{equation}
where \(L\) is an arbitrary real number that defines the discretization level of the RTD. In practice BISIP uses \(L = 2\times n_{freq}\), where \(n_{freq}\) is the number of measurement points in the frequency range. The RTD is defined by the distribution of \(m_l\) values as a function of \(\tau_l\) values. According to Keery et al. (2012), the RTD can be written as
\begin{equation} m_l = \sum_{p=0}^P a_p (\log_{10} \tau_l)^p, \end{equation}
where \(a_p\) are polynomial coefficients and \(P\) is the polynomial degree of the approximation. In practice, \(P\) is often set to 3, 4 or 5. The user should aim to use the lowest degree possible while maintaining a satisfying fit with the data. As a result, \(\rho^*\) depends on \(P+1\) parameters:
\(\rho_0 \in [0, \infty)\), the direct current resistivity \(\rho_0 = \rho^*(\omega\to 0)\).
\(a_p\), the \(P\) polynomial coefficients.
From the recovered \(a_p\) and \(\rho_0\) values, the user can then compute the RTD and extract several integrating parameters, such as total chargeability and mean relaxation time. The user is referred to Keery et al. (2012) for the definition of these parameters. In this tutorial, we will compare the total chargeability values obtained with Debye and Warburg decomposition for 5 rock samples.
Debye decomposition
First import the required packages.
[2]:
import numpy as np
from bisip import PolynomialDecomposition
from bisip import DataFiles
np.random.seed(42)
Let’s start by inspecting the data sets so we can decide which polynomial approximation would be appropriate to fit the observations.
[3]:
data_files = DataFiles() # get the dictionary of BISIP data files
for n, p in data_files.items(): # n is the filename, p the filepath
model = PolynomialDecomposition(filepath=p)
fig = model.plot_data('phase')
ax = fig.gca()
ax.set_title(n)
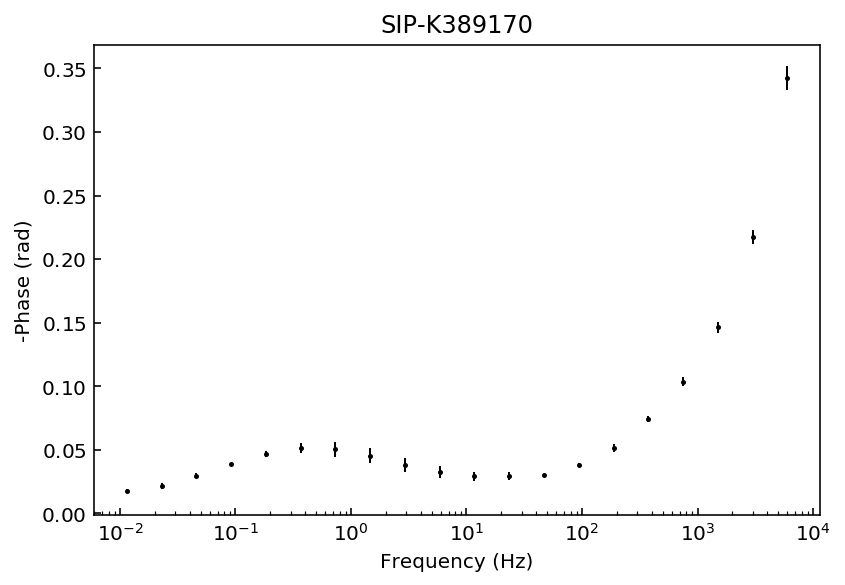
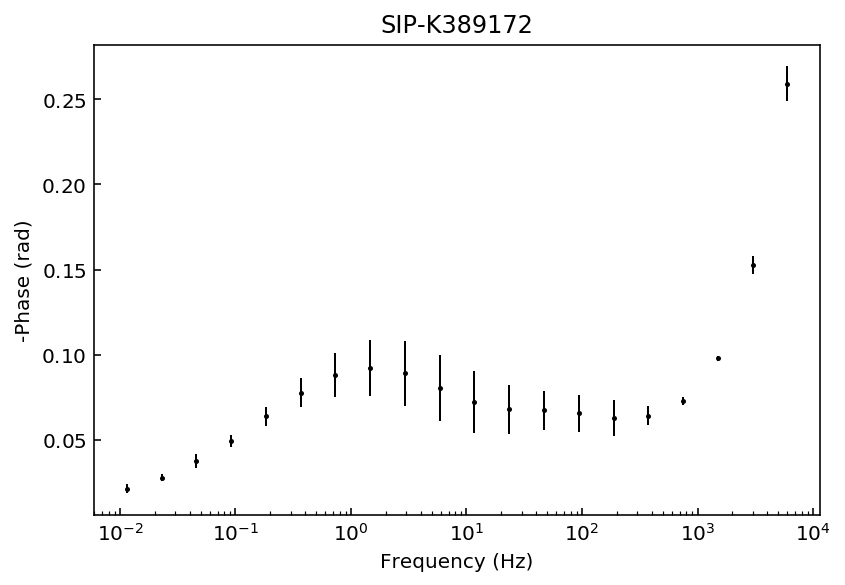
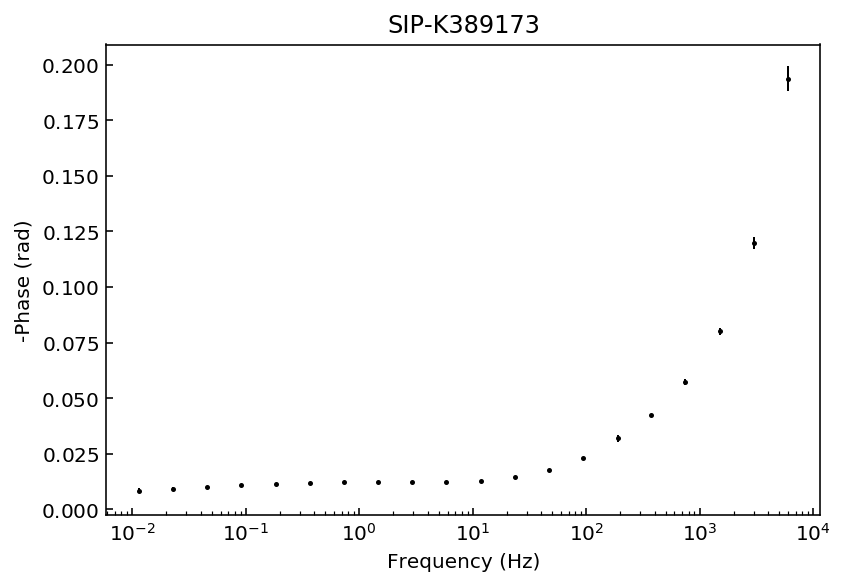
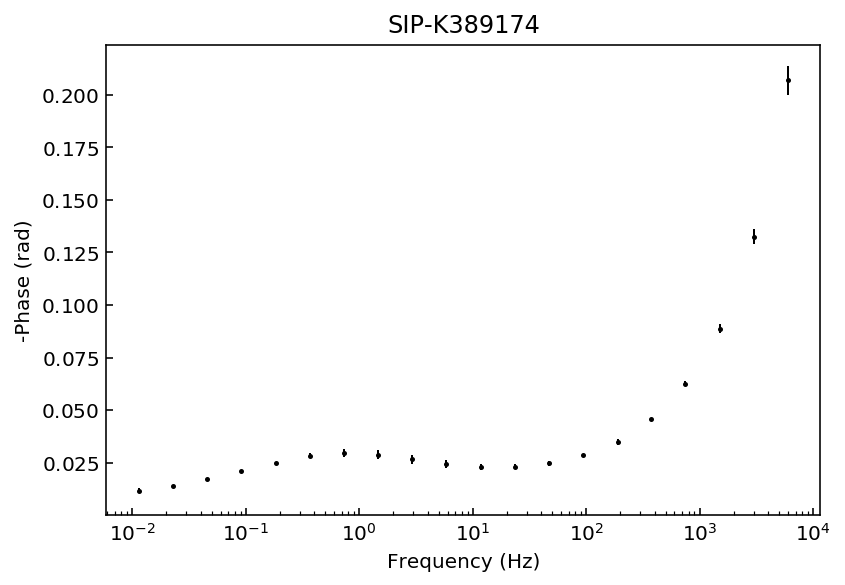
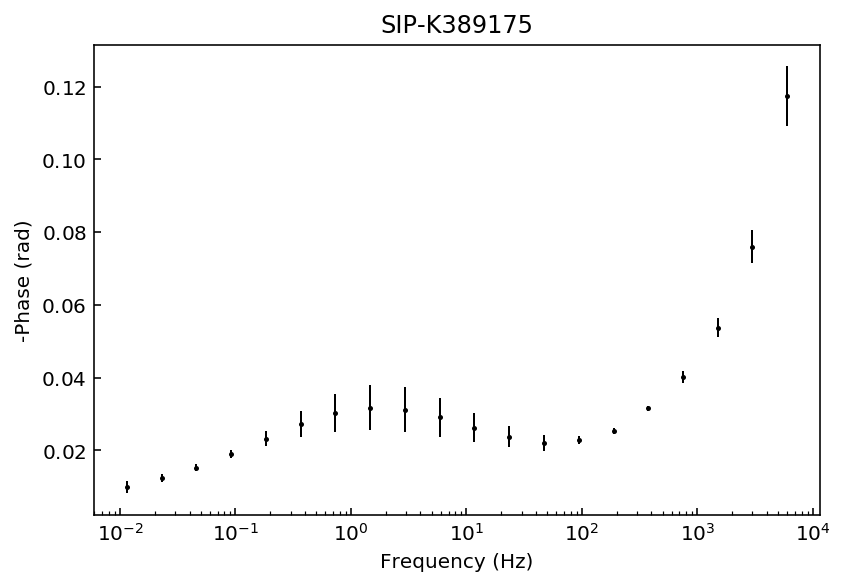
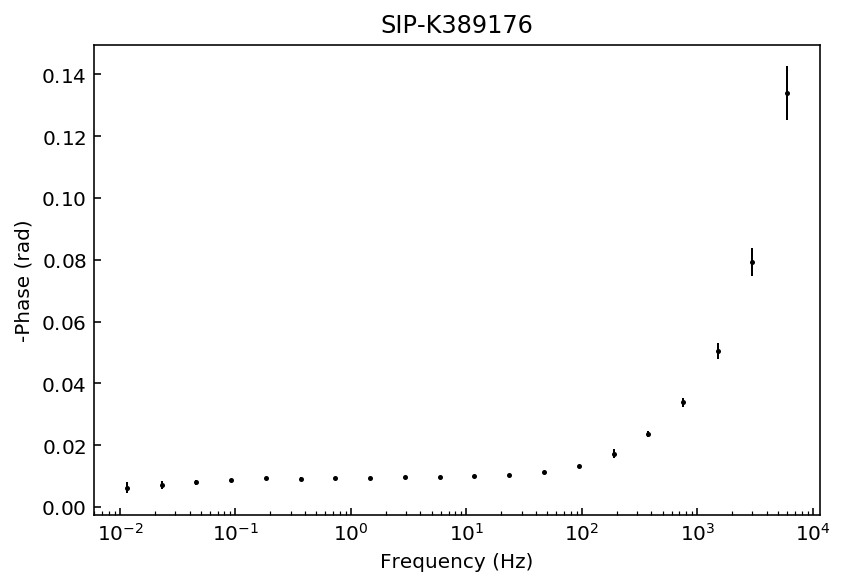
Samples K389173 and K389176 can be explained with a 3rd degree polynomial approxation, whereas the rest of the samples would likely require a 4th order polynomial approximation. For this example we will use a 4th order approaximation for all data sets.
[4]:
# Make a dict to hold results
results_debye = {}
# Define MCMC and Debye parameters
params = {'nwalkers': 32,
'nsteps': 1000,
'c_exp': 1,
'poly_deg': 4,
}
for n, p in data_files.items(): # n is the filename, p the filepath
# Initialize with 1 file at a time, and pass the params
model = PolynomialDecomposition(filepath=p, **params)
model.fit()
# Store the fitted model in the results dict
results_debye[n] = model
100%|██████████| 1000/1000 [00:01<00:00, 505.89it/s]
100%|██████████| 1000/1000 [00:01<00:00, 512.17it/s]
100%|██████████| 1000/1000 [00:01<00:00, 508.69it/s]
100%|██████████| 1000/1000 [00:01<00:00, 509.93it/s]
100%|██████████| 1000/1000 [00:01<00:00, 532.47it/s]
100%|██████████| 1000/1000 [00:01<00:00, 522.29it/s]
Now we have a dictionary of fitted models in results_debye. Let’s quickly inspect the fit results while discarding half the steps as burn-in. Check the chains with the plot_traces() method to see why the value is appropriate.
[5]:
for name, model in results_debye.items():
fig = model.plot_fit_pa(discard=500)
ax = fig.gca()
ax.set_title(n)
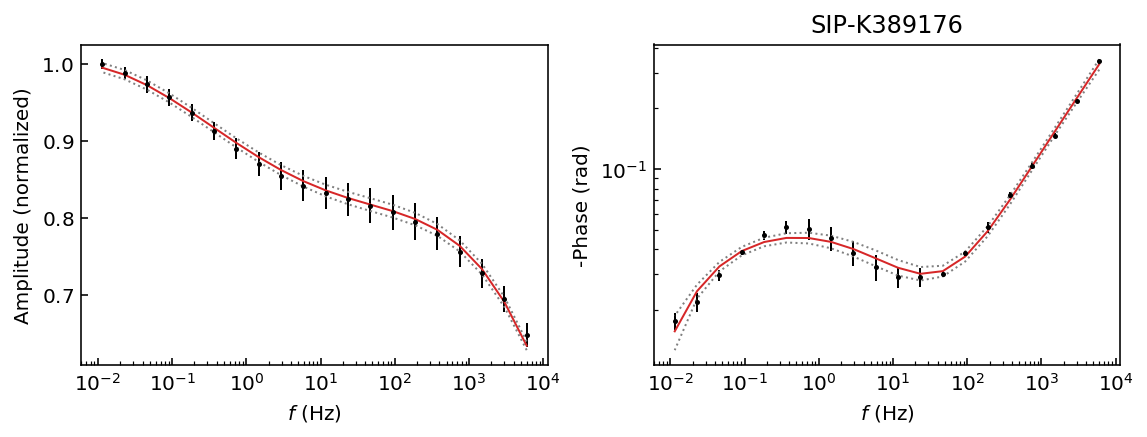
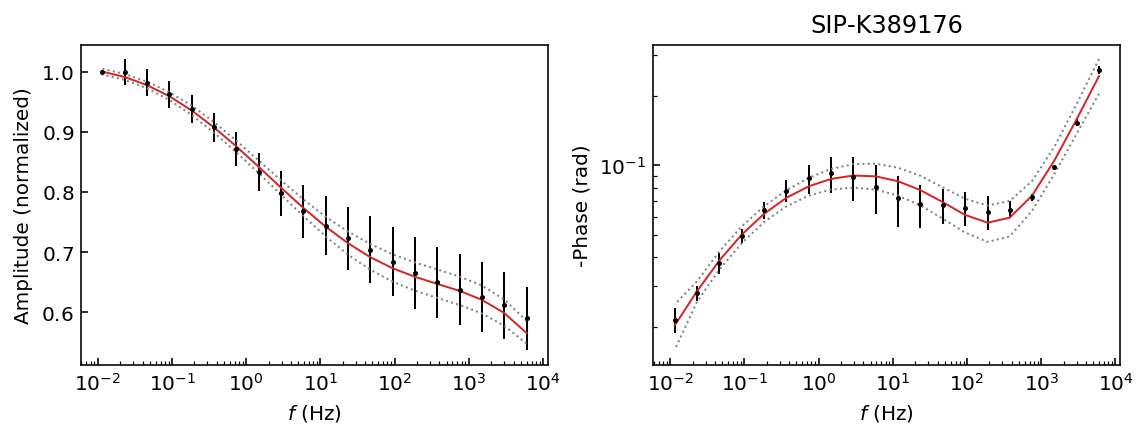
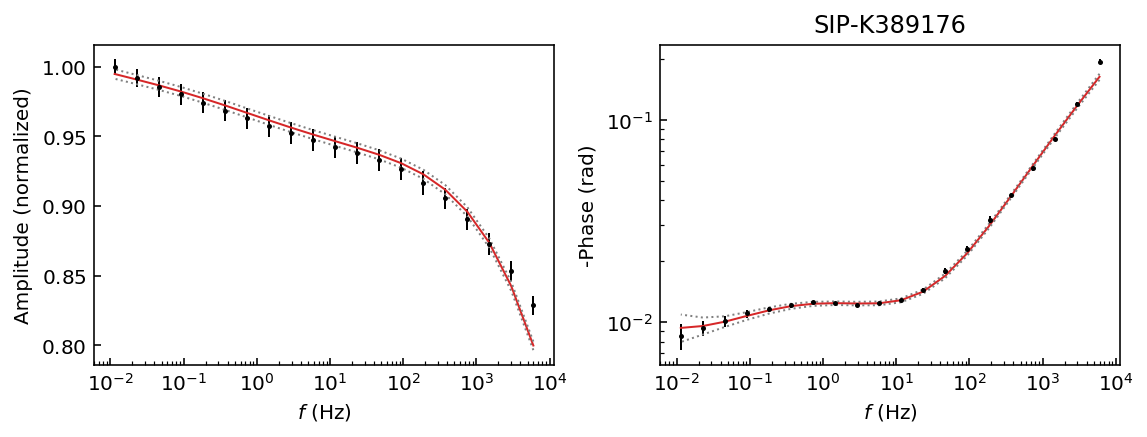
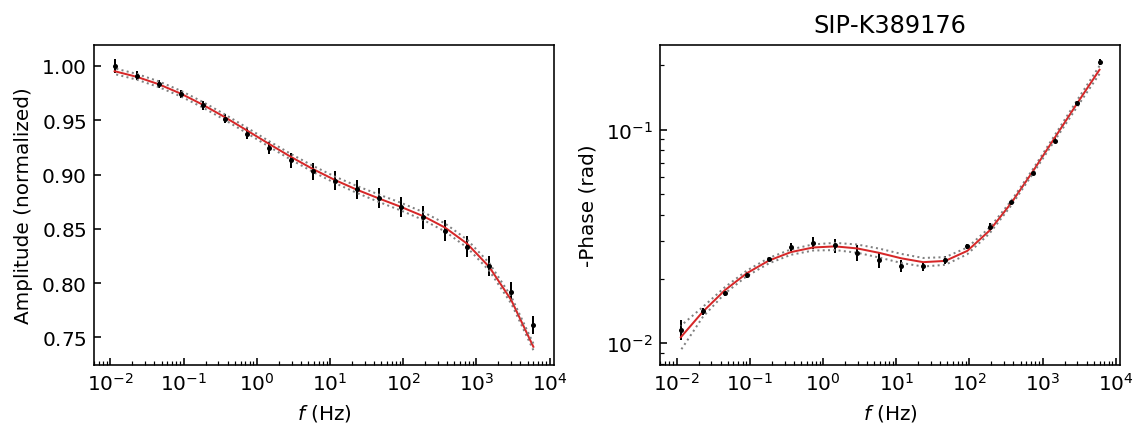
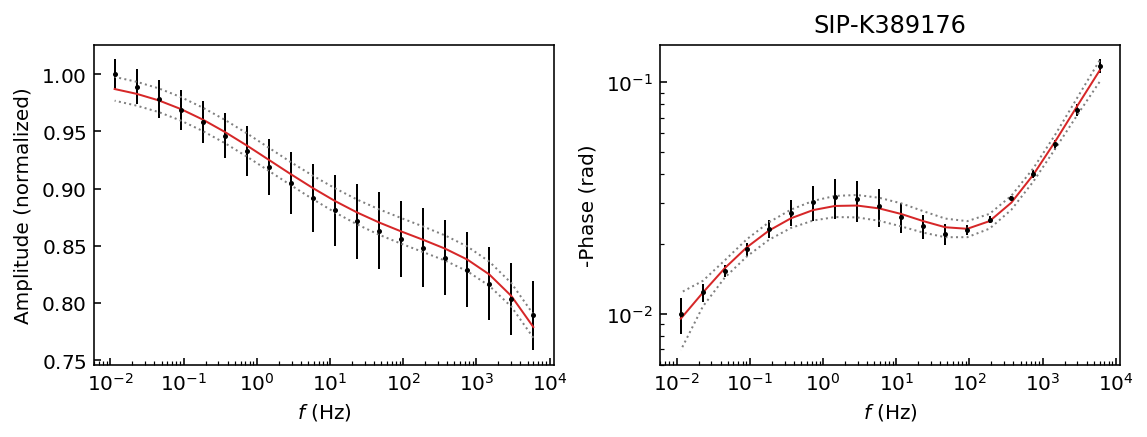
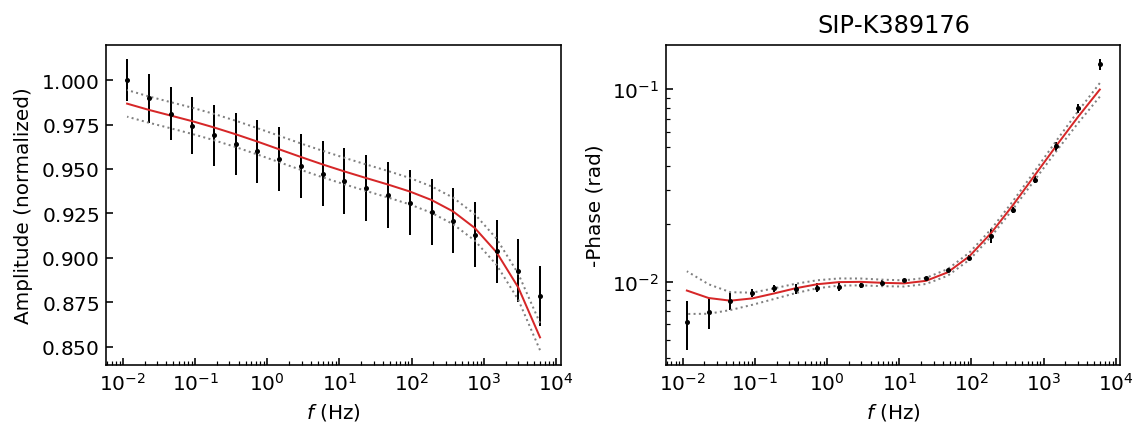
We have obtained a good fit and 95% HPD for all data sets. This is interesting because we have a unique solution for each data set. Therefore, our recovered values should be usable for all samples, whereas if we used a Cole-Cole model samples K389173 and K389176 would have a ill-defined solution (see the Pelton tutorial).
We need to do a bit of work to extract the total chargeability. We will use the pandas library to organize the results in a DataFrame.
[6]:
import pandas as pd
names, models = zip(*results_debye.items())
mean_values = [m.get_param_mean(discard=500) for m in models]
df_debye = pd.DataFrame(mean_values)
df_debye.columns= models[0].param_names
df_debye.index = names
df_debye.head(6)
[6]:
| r0 | a0 | a1 | a2 | a3 | a4 | |
|---|---|---|---|---|---|---|
| SIP-K389170 | 0.989771 | 0.014033 | -0.002350 | -0.004634 | -0.000338 | 0.000219 |
| SIP-K389172 | 1.018388 | 0.017680 | -0.011578 | -0.003509 | 0.002061 | 0.000526 |
| SIP-K389173 | 1.011923 | 0.003390 | -0.000995 | -0.000499 | 0.000396 | 0.000172 |
| SIP-K389174 | 1.004851 | 0.007547 | -0.003206 | -0.001871 | 0.000548 | 0.000242 |
| SIP-K389175 | 0.997613 | 0.006870 | -0.003937 | -0.001338 | 0.000741 | 0.000219 |
| SIP-K389176 | 1.006941 | 0.002426 | -0.001084 | -0.000048 | 0.000564 | 0.000159 |
We need to sum the coefficients and log_tau values:
\begin{equation} m_l = \sum_{p=0}^P a_p (\log_{10} \tau_l)^p. \end{equation}
[7]:
# Take log_tau from any model (considering the
# frequency range is the same for all samples)
log_tau = models[0].log_tau
print(log_tau)
[-6. -5.79487179 -5.58974359 -5.38461538 -5.17948718 -4.97435897
-4.76923077 -4.56410256 -4.35897436 -4.15384615 -3.94871795 -3.74358974
-3.53846154 -3.33333333 -3.12820513 -2.92307692 -2.71794872 -2.51282051
-2.30769231 -2.1025641 -1.8974359 -1.69230769 -1.48717949 -1.28205128
-1.07692308 -0.87179487 -0.66666667 -0.46153846 -0.25641026 -0.05128205
0.15384615 0.35897436 0.56410256 0.76923077 0.97435897 1.17948718
1.38461538 1.58974359 1.79487179 2. ]
Define this utility function to get the chargeability value (\(m\)) that corresponds to each \(\tau\) value.
[8]:
def get_m(df, P):
m = {}
for idx in df.index:
m[idx] = 0
for p in range(P+1):
coeff = df_debye.loc[idx, f'a{p}']
m[idx] += coeff*log_tau**p
# Add the total chargeability in the df
df.loc[idx, 'total_m'] = np.sum(m[idx])
return m
m_debye = get_m(df_debye, params['poly_deg'])
df_debye.head(6)
[8]:
| r0 | a0 | a1 | a2 | a3 | a4 | total_m | |
|---|---|---|---|---|---|---|---|
| SIP-K389170 | 0.989771 | 0.014033 | -0.002350 | -0.004634 | -0.000338 | 0.000219 | 1.342871 |
| SIP-K389172 | 1.018388 | 0.017680 | -0.011578 | -0.003509 | 0.002061 | 0.000526 | 1.210898 |
| SIP-K389173 | 1.011923 | 0.003390 | -0.000995 | -0.000499 | 0.000396 | 0.000172 | 0.786556 |
| SIP-K389174 | 1.004851 | 0.007547 | -0.003206 | -0.001871 | 0.000548 | 0.000242 | 0.930805 |
| SIP-K389175 | 0.997613 | 0.006870 | -0.003937 | -0.001338 | 0.000741 | 0.000219 | 0.655028 |
| SIP-K389176 | 1.006941 | 0.002426 | -0.001084 | -0.000048 | 0.000564 | 0.000159 | 0.545386 |
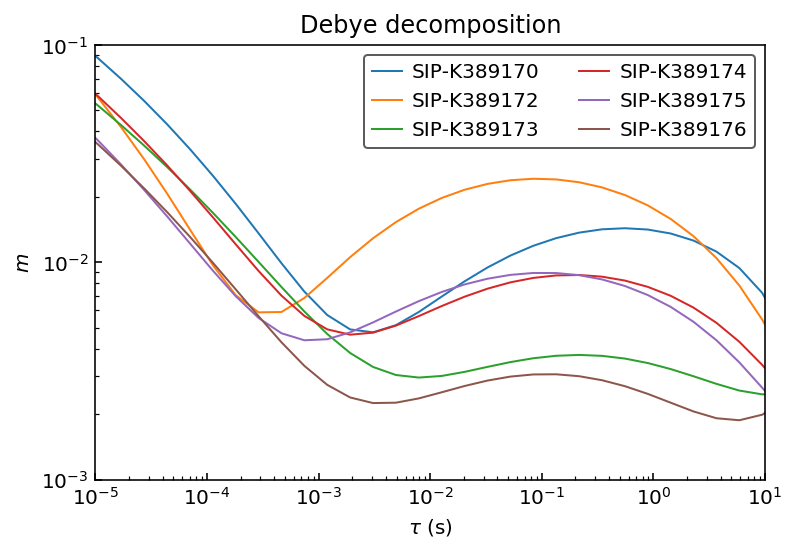
Let’s inspect the recovered RTDs:
[9]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
for n in names:
ax.plot(10**log_tau, m_debye[n], label=n)
ax.set_ylabel(r'$m$')
ax.set_xlabel(r'$\tau$ (s)')
ax.set_title('Debye decomposition')
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_xlim([1e-5, 1e1])
ax.set_ylim([1e-3, 1e-1])
ax.legend(ncol=2)
[9]:
<matplotlib.legend.Legend at 0x116aed160>
Warburg decomposition
Now we will repeat these steps for a Warburg decomposition (\(c = 0.5\)).
[10]:
# Make a dict to hold results
results_warburg = {}
# Define MCMC and Debye parameters
params = {'nwalkers': 32,
'nsteps': 1000,
'c_exp': 0.5,
'poly_deg': 4,
}
for n, p in data_files.items(): # n is the filename, p the filepath
# Initialize with 1 file at a time, and pass the params
model = PolynomialDecomposition(filepath=p, **params)
model.fit()
# Store the fitted model in the results dict
results_warburg[n] = model
100%|██████████| 1000/1000 [00:03<00:00, 262.07it/s]
100%|██████████| 1000/1000 [00:03<00:00, 265.81it/s]
100%|██████████| 1000/1000 [00:03<00:00, 263.03it/s]
100%|██████████| 1000/1000 [00:03<00:00, 264.32it/s]
100%|██████████| 1000/1000 [00:03<00:00, 269.38it/s]
100%|██████████| 1000/1000 [00:03<00:00, 268.75it/s]
[11]:
names, models = zip(*results_debye.items())
mean_values = [m.get_param_mean(discard=500) for m in models]
df_warburg = pd.DataFrame(mean_values)
df_warburg.columns= models[0].param_names
df_warburg.index = names
m_warburg = get_m(df_warburg, params['poly_deg'])
df_warburg.head(6)
[11]:
| r0 | a0 | a1 | a2 | a3 | a4 | total_m | |
|---|---|---|---|---|---|---|---|
| SIP-K389170 | 0.989771 | 0.014033 | -0.002350 | -0.004634 | -0.000338 | 0.000219 | 1.342871 |
| SIP-K389172 | 1.018388 | 0.017680 | -0.011578 | -0.003509 | 0.002061 | 0.000526 | 1.210898 |
| SIP-K389173 | 1.011923 | 0.003390 | -0.000995 | -0.000499 | 0.000396 | 0.000172 | 0.786556 |
| SIP-K389174 | 1.004851 | 0.007547 | -0.003206 | -0.001871 | 0.000548 | 0.000242 | 0.930805 |
| SIP-K389175 | 0.997613 | 0.006870 | -0.003937 | -0.001338 | 0.000741 | 0.000219 | 0.655028 |
| SIP-K389176 | 1.006941 | 0.002426 | -0.001084 | -0.000048 | 0.000564 | 0.000159 | 0.545386 |
Add the Debye and Warburg values to a single DataFrame and print it.
[12]:
df = pd.merge(df_debye, df_warburg,
left_index=True, right_index=True,
suffixes=('_Debye', '_Warburg'))
df[['total_m_Debye', 'total_m_Warburg']].head(6)
[12]:
| total_m_Debye | total_m_Warburg | |
|---|---|---|
| SIP-K389170 | 1.342871 | 1.342871 |
| SIP-K389172 | 1.210898 | 1.210898 |
| SIP-K389173 | 0.786556 | 0.786556 |
| SIP-K389174 | 0.930805 | 0.930805 |
| SIP-K389175 | 0.655028 | 0.655028 |
| SIP-K389176 | 0.545386 | 0.545386 |
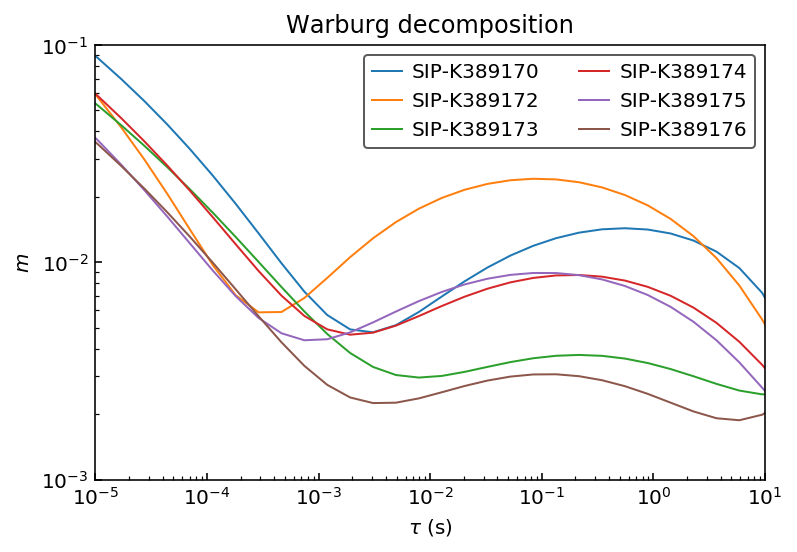
The values are identical. Finally let’s look at the RTDs to confirm that they are the same.
[13]:
fig, ax = plt.subplots()
for n in names:
ax.plot(10**log_tau, m_debye[n], label=n)
ax.set_ylabel(r'$m$')
ax.set_xlabel(r'$\tau$ (s)')
ax.set_title('Warburg decomposition')
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_xlim([1e-5, 1e1])
ax.set_ylim([1e-3, 1e-1])
ax.legend(ncol=2)
[13]:
<matplotlib.legend.Legend at 0x116198828>
Conclusions
In this tutorial we have seen how to do batch inversions, organize the results in pandas DataFrames and how to extract integrating parameters from the polynomial decomposition approach. The total chargeability parameter was identical for Debye and Warburg decomposition approaches.